Exact Match Evaluation
The simplest evaluation type is direct string comparison. LangChain has a prebuilt "exact match" evaluator you can use, or you can do the same with a custom evaluator.
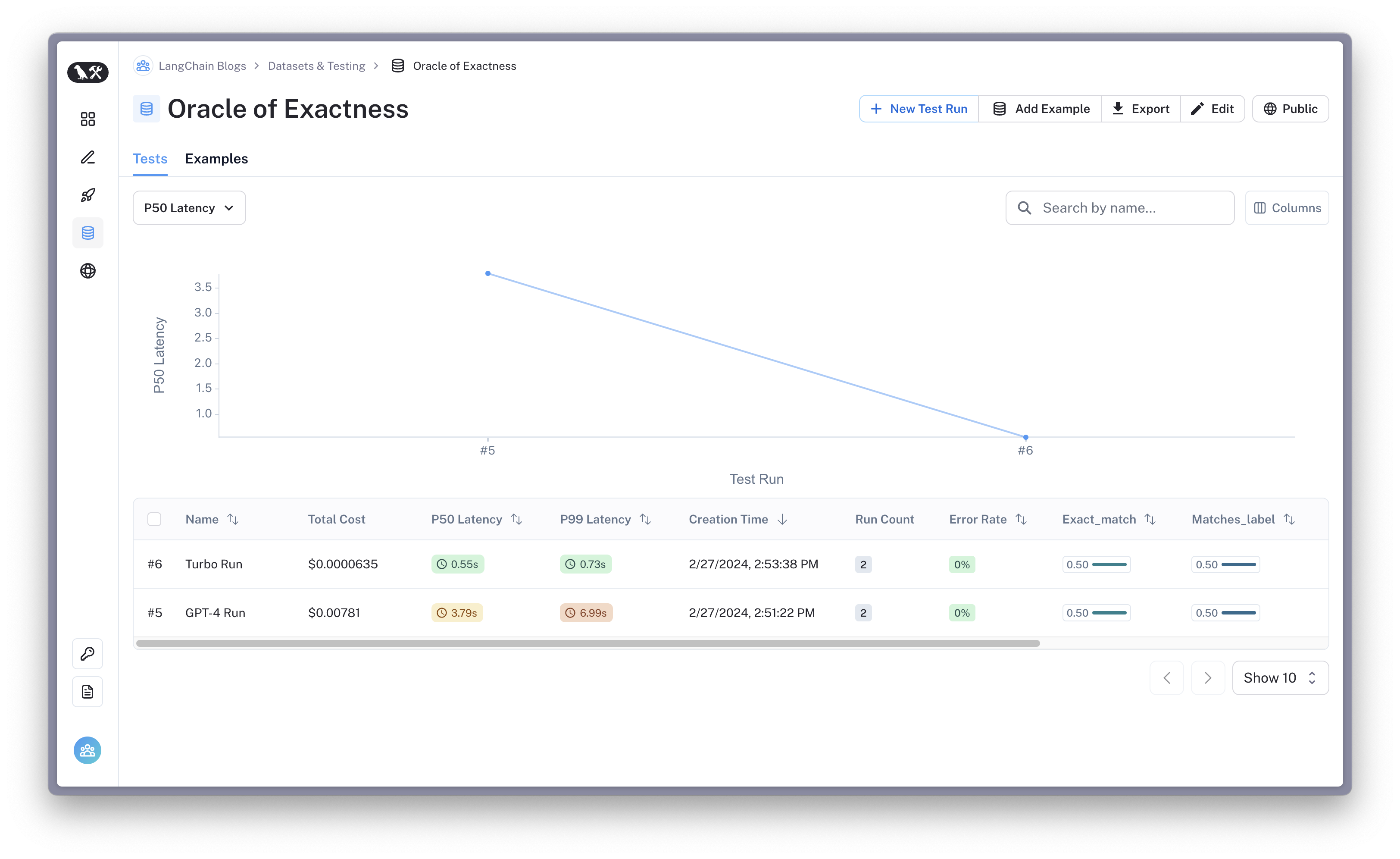
You can check out the example results here.
# %pip install -U --quiet langchain langchain_openai
import os
# Update with your API URL if using a hosted instance of Langsmith.
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
# Update with your API key
os.environ["LANGCHAIN_API_KEY"] = "YOUR API KEY"
os.environ["OPENAI_API_KEY"] = "Your openai api key"
Create Dataset
First you create a simple dataset of input and expected output pairs.
import langsmith
client = langsmith.Client()
dataset_name = "Oracle of Exactness"
if not client.has_dataset(dataset_name=dataset_name):
ds = client.create_dataset(dataset_name)
client.create_examples(
inputs=[
{
"prompt_template": "State the year of the declaration of independence."
"Respond with just the year in digits, nothign else"
},
{"prompt_template": "What's the average speed of an unladen swallow?"},
],
outputs=[{"output": "1776"}, {"output": "5"}],
dataset_id=ds.id,
)
Evaluate
from langchain.smith import RunEvalConfig
from langchain_openai import ChatOpenAI
from langsmith.evaluation import EvaluationResult, run_evaluator
model = "gpt-3.5-turbo"
# This is your model/system that you want to evaluate
def predict_result(input_: dict) -> dict:
response = ChatOpenAI(model=model).invoke(input_["prompt_template"])
return {"output": response.content}
@run_evaluator
def compare_label(run, example) -> EvaluationResult:
# Custom evaluators let you define how "exact" the match ought to be
# It also lets you flexibly pick the fields to compare
prediction = run.outputs.get("output") or ""
target = example.outputs.get("output") or ""
match = prediction and prediction == target
return EvaluationResult(key="matches_label", score=match)
# This defines how you generate metrics about the model's performance
eval_config = RunEvalConfig(
evaluators=["exact_match"], # equivalent prebuilt evaluator
custom_evaluators=[compare_label],
)
client.run_on_dataset(
dataset_name=dataset_name,
llm_or_chain_factory=predict_result,
evaluation=eval_config,
verbose=True,
project_metadata={"version": "1.0.0", "model": model},
)
View the evaluation results for project 'impressionable-crew-29' at:
https://smith.langchain.com/o/30239cd8-922f-4722-808d-897e1e722845/datasets/4f23ec54-3cf8-44fc-a729-ce08ad855bfd/compare?selectedSessions=a0672ba4-e513-4fef-84b8-bab439581721
View all tests for Dataset Oracle of Exactness at:
https://smith.langchain.com/o/30239cd8-922f-4722-808d-897e1e722845/datasets/4f23ec54-3cf8-44fc-a729-ce08ad855bfd
[------------------------------------------------->] 2/2
<h3>Experiment Results:</h3>
| feedback.exact_match | feedback.matches_label | error | execution_time | run_id | count | unique | top | freq | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2.000000 | 2 | 0 | 2.000000 | 2 | ||||||||||||
| NaN | 2 | 0 | NaN | 2 | ||||||||||||
| NaN | False | NaN | NaN | 2b4532af-445e-46aa-8170-d34c3af724a8 | ||||||||||||
| NaN | 1 | NaN | NaN | 1 | ||||||||||||
| 0.500000 | NaN | NaN | 0.545045 | NaN | ||||||||||||
| 0.707107 | NaN | NaN | 0.265404 | NaN | ||||||||||||
| 0.000000 | NaN | NaN | 0.357376 | NaN | ||||||||||||
| 0.250000 | NaN | NaN | 0.451211 | NaN | ||||||||||||
| 0.500000 | NaN | NaN | 0.545045 | NaN | ||||||||||||
| 0.750000 | NaN | NaN | 0.638880 | NaN | ||||||||||||
| 1.000000 | NaN | NaN | 0.732714 | NaN |
{'project_name': 'impressionable-crew-29',
'results': {'893730f0-393d-4c40-92f9-16ce24aaec1f': {'input': {'prompt_template': "What's the average speed of an unladen swallow?"},
'feedback': [EvaluationResult(key='exact_match', score=0, value=None, comment=None, correction=None, evaluator_info={'__run': RunInfo(run_id=UUID('089a016a-d847-4a26-850c-afc0e78879d5'))}, source_run_id=None, target_run_id=None),
EvaluationResult(key='matches_label', score=False, value=None, comment=None, correction=None, evaluator_info={}, source_run_id=None, target_run_id=None)],
'execution_time': 0.732714,
'run_id': '2b4532af-445e-46aa-8170-d34c3af724a8',
'output': {'output': 'The average speed of an unladen European swallow is approximately 20.1 miles per hour (32.4 km/h).'},
'reference': {'output': '5'}},
'ec9d8754-d264-4cec-802e-0c33513843d8': {'input': {'prompt_template': 'State the year of the declaration of independence.Respond with just the year in digits, nothign else'},
'feedback': [EvaluationResult(key='exact_match', score=1, value=None, comment=None, correction=None, evaluator_info={'__run': RunInfo(run_id=UUID('cd4c7ede-f367-4d9c-b424-577bf054bf21'))}, source_run_id=None, target_run_id=None),
EvaluationResult(key='matches_label', score=True, value=None, comment=None, correction=None, evaluator_info={}, source_run_id=None, target_run_id=None)],
'execution_time': 0.357376,
'run_id': '82b65c5c-bfbf-4d2b-9c05-3bbd1cd4e711',
'output': {'output': '1776'},
'reference': {'output': '1776'}}}}